Some Inter–disciplinary projects for Math,
CS Statistics, Physics, Biology and Economics
The inter-disciplinary programming projects P1-P11 and SP1- SP4 are asking questions in different areas: Calculus (graphing and solving equations), Differential Equations ( Euler and Runge-Kutta methods), Statistics, Physics (Newton’s Law of cooling), Biology (spreading of epidemics), Economics. Some projects will require programs in either C, C++ or Java. Some other projects will ask the student to use existing programs or write additional programs that use some already created programs as tools to answer questions in areas like Physics, Biology, Economics etc.
Section1: Projects for Computer Science, Mathematics,
Statistics
P1. Euler’s method for solving ordinary differential equations:
Successive Approximation using Euler's Method
The process of
generating a sequence of approximations to the same thing is called successive approximation. If we run Euler's Method with one step size,
we get one piecewise linear approximation to the solution of the initial value
problem. If we run it again with
another (generally smaller) step size, we get another approximation. If we run it yet again with another
(generally smaller) step size, we get yet another approximation. In this way we can generate a sequence of
piecewise-linear approximations to the solution.
Write a subroutine Euler1 to implement the Euler’s method
described bellow for solving differential equations y ' =
f(x,y) with given initial value
numerically.
Successive
Approximation with Euler's Method
An important
feature of Euler's Method is the input step size. One approximation to the
solution can be computed using a given step size. Then the step size can be made smaller and another approximation
obtained. The step size can be made
even smaller and yet another
approximation obtained. This process is
called successive
approximation.
Successive
approximations produced by Euler's Method generally appear to stabilize
. That is, eventually a decrease
in the step size produces little change in the approximation. Under a hypothesis motivated by observing
this pattern of stabilization, we will show that Euler's Method actually converges to the true solution. At a
given input value, our technique will also enable us to estimate the output
value to which Euler's Method converges.
Select an
increment Dx, or compute it
for a given number of iterations n then
Dx =
(b-a)/n. Your solution will be a
piece-wise linear function repeating the following step:
Calculate the
approximate solution y![]() at x
at x![]() = x
= x ![]() + D x is given by:
+ D x is given by:
y![]() = y
= y![]() + Dx f( x
+ Dx f( x![]() , y
, y![]() )
)
Question 1:
Write an applet that takes input from the user: the initial value x![]() and the
step-size or the number of steps and the final value and uses the Euler method
to solve the differential equation. Show your results both as a table of values
and a function graph. Test your program solving the differential equation y' = ─ 4y with initial
conditions y(0)=1 . This is called an IVP , initial value
problem. What is the value of y(2) ?
and the
step-size or the number of steps and the final value and uses the Euler method
to solve the differential equation. Show your results both as a table of values
and a function graph. Test your program solving the differential equation y' = ─ 4y with initial
conditions y(0)=1 . This is called an IVP , initial value
problem. What is the value of y(2) ?
Question 2: Euler method for a system of 2
equations Write a program Euler2 to
implement the Euler’s method described bellow for solving a system y’= f ( x, y, z), z’= g ( x, y, z) of 2 first order differential equations numerically. Select an increment Dx. The approximate
solutions y![]() and z
and z![]() at x
at x![]() = x
= x ![]() + D x are given by:
+ D x are given by:
y![]() = y
= y![]() + Dx f( x
+ Dx f( x![]() , y
, y![]() , z
, z![]() ) , and z
) , and z![]() = z
= z![]() + Dx g( x
+ Dx g( x![]() , y
, y![]() , z
, z![]() )
)
Test your
program solving y' = - 4y , z’ = 2z with initial conditions: y(0)=1 . z(0)=1. What is the value
of y(2), and z(2) ? Give your answer both as two tables of values and two function graphs.
Question 3: Euler method for a system of 3
equations: Write a program Euler3 to implement the Euler’s method
described bellow for solving the system:
y’= f( x, y, z, w), z’= g( x, y,
z, w) , w’= h( x, y, z, w)
of 3 first order ordinary differential equations
numerically.
Select an
increment D x . The approximate
solutions y![]() , z
, z![]() and w
and w![]() at x
at x![]() = x
= x![]() + D x are given by:
y
+ D x are given by:
y![]() = y
= y![]() + Dx f( x
+ Dx f( x![]() , y
, y![]() , z
, z![]() w
w![]() ),
),
z![]() = z
= z![]() + Dx g( x
+ Dx g( x![]() , y
, y![]() , z
, z![]() w
w![]() ) and w
) and w![]() = w
= w![]() + Dx g( x
+ Dx g( x![]() , y
, y![]() , z
, z![]() ,w
,w![]() )
)
Test your
program solving y' = - 4y , z = 2z, w’=w with initial conditions: y(0)=1, z(0)=1, w(0)=2 .What are the
values of y(2), z(2) and w(2) ?
Give your answer
both as three tables of values as well
as function graphs.
Question 4: Is it better to
just run Euler's Method once with a small step size, or several times with
smaller step sizes each time?
1. How accurate
is the approximation?
2. How can the
approximation be improved?
Which
approximations (those based on Δ t = 0.1 or those based on Δ t = 0.2 gave the smaller difference between the
estimated and actual values at t = 0 ?
Based on this
experience, and your experience with Euler's Method for Newton's Law of
Cooling, can you propose a relationship between the step-size of Euler's Method
and the accuracy of approximations calculated using it?
You know that
Euler's Method can be used to find approximate solutions to initial value
problems. what can you say about the accuracy of these approximations? What evidence do you have to support your
claims?
P2. Runge-Kutta method for differential equations
Question : The Runge-Kutta method
described bellow has a superior accuracy for solving differential equations
numerically.
The
Runge-Kutta method solving the ordinary differential equation
y' = f(x,y) with
given initial values x![]() , y
, y![]() :
:
Select an
increment D x . The
approximate solution y![]() at x
at x![]() = x
= x ![]() + D x
+ D x
is given by:
y ![]() = y
= y![]() + (1/6)( K1 + K2 + K3 + K4) where
+ (1/6)( K1 + K2 + K3 + K4) where
K1 = Dx f( x![]() , y
, y![]() ) ,
) ,
K2 = Dx f( x![]() +D x /2, y
+D x /2, y![]() + K1/2)
+ K1/2)
K3 = Dx f(x![]() +D x /2, y
+D x /2, y![]() + K2/2)
+ K2/2)
K4 = Dx f(x![]() +Dx, y
+Dx, y![]() + K3)
+ K3)
Question 1: Write a function to implement the Runge-Kutta method
for solving differential equations numerically Test your program solving the
equation y' = ─ 4y with initial conditions: y(0)=1. What is
the value of y(3) ?
Question 2 : Write an applet that takes input from
the user: the initial value x![]() and the step-size and final value and uses the Runge-Kutta
method to solve the differential equation and post the answers as both a table
of values and a function graph
and the step-size and final value and uses the Runge-Kutta
method to solve the differential equation and post the answers as both a table
of values and a function graph
P3 Graphing
functions, solving equations numerically
Graphing
functions, a Java project Create an applet to draw a graph of a function given in Cartesian or parametric coordinates. You
need to draw n line segments joining the successive points (x, f(x)) and (x + d, f(x +
d)) (or two points (x(t), y(t)) and (x(t+d) y(t+d)) if using parametric coordinates).
Find a root of a function by bisection method
The method starts with two numbers a and b
where the function values f(a) and f(b) have opposite signs. If f is continuous
between x=a and x=b then the graph of f
must cross the x-axis at least once in the interval [a,b] and thus the equation
f(x)=0 has at least one solution in the interval [a,b]. To locate one of these
solutions we first bisect the interval [a, b]( i.e. take the midpoint (a+b)/2 )
and determine in which half the function f(x) changes sign, thereby locating a
smaller subinterval containing the solution of the equation. Repeating this
process gives a sequence of subintervals, each of which contains a solution of
the equation f(x)=0 and has length one-half that of the preceding interval. End
the iteration process when you reach
the desired precision (say to get 5 exact decimals the length of the interval
should be less then 1/1000000).
Question 1: Write a Java program to graph the function and help visualize the
solution. Create an applet to draw a graph of a function given in Cartesian or parametric coordinates.
Experiment with values of n = 10, 25,
50, 100, 200 to make the best choice. Draw the graphs of the following three
functions:
a) f(x) = x![]() + x - 3 on the interval [0, 4]
+ x - 3 on the interval [0, 4]
b) g(x) = x![]() /100 - x + 10 on the interval [-10, 10]
/100 - x + 10 on the interval [-10, 10]
c) "The
four-leaved rose" whose equation in polar coordinates is r = cos2q with 0 < q < 2 p .
Question 2: Find a root of a function by bisection method
Write a Java application to find an approximate
the root of the function
f(x) = x![]() + x - 3 in the interval [ 1, 2] using the bisection method
+ x - 3 in the interval [ 1, 2] using the bisection method
P4 Simpson’s
method for definite integrals
Approximate the integral of a function using Simpson’s method
Write a Java application/applet program that approximates the integral of the function over the interval [a, b] using Simpson's rule,(the best method at hand!).
In Simpson's method we take a division of the
interval [a, b] with an even number of 2n
equidistant nodes of the interval [a, b] given by
x![]() = a+ (k-1)
= a+ (k-1)![]() , so Dx =
, so Dx = ![]() and the integral is approximated by:
and the integral is approximated by:
![]() [ f(x
[ f(x![]() )+4 f(x
)+4 f(x![]() )+2 f(x
)+2 f(x![]() )+4 f(x
)+4 f(x![]() )+2 f(x
)+2 f(x![]() )+¼+ 2f( x
)+¼+ 2f( x![]() )+4 f(x
)+4 f(x![]() )+f(x
)+f(x![]() )]
)]
Question 1 : Find an
approximate value of
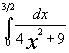
the area under the graph of the function f(x)= 1/( 4x![]() +9) from x=0 to
x=3/2 i.e. (the definite
integral from x=0 to x= 3/2 of the function f(x)= 1/(4 x
+9) from x=0 to
x=3/2 i.e. (the definite
integral from x=0 to x= 3/2 of the function f(x)= 1/(4 x![]() + 9) ). Input: a, b,
the endpoints of the interval of integration
and n the number of subintervals
used, f(x) the integrand Output: Simpson’s -rule
approximation to integral of f(x) from a to b
+ 9) ). Input: a, b,
the endpoints of the interval of integration
and n the number of subintervals
used, f(x) the integrand Output: Simpson’s -rule
approximation to integral of f(x) from a to b
Question 2: Write an applet
showing both the graph of the given function and the n (colored) rectangles
used by the Riemann sum approximation. The number of rectangles will be
determined at run time by user's input.
For input you can use the class InteractiveIO from the textbook and the
Integer.parseInt(),or Double.parseDouble().
You can use a dialog box (a modal dialog) for input (we shall use the
static method showInputDialog() of the JOptionPane class which is within the
javax.swing package like this:
String name=
newJOptionPane.showInputDialog(" Please enter your data:")
P5. Statistics and probability
Part 1. You are
working for the census bureau and you need to write a program to count the number of people in each of the
following age groups: 0 - 16 infant, 16 - 29 young, 29 - 55 middle aged, 55 -
75 old, 75 - and older, really
old.
The bureau needs
some statistics regarding the distribution of ages.
Question 1: Write a program
to read in an unknown variable number of ages.
Report the
number of people in each age group
Question 2: Compute the mean
m (i.e. the
average) age and the mode (i.e. the age that occurs most frequently - note that occasionally some of the ages
might be the same). Ages should be read in as integers, but the average should
be a
real number in
double precision. Calculate also the
standard deviation.
Question 3: Write a Java
applet to calculate the mean, variance and standard deviation for a given
set of numbers. The user in entering the data interactively The size of the
data set will be determined at run
time.
Recall the
following formulas:
Mean m = ![]() ,
,
Variance V = s![]() =
= ![]() -
- ![]() (
( ![]() )
)![]() ,
,
Standard deviation s = ![]()
Part 2. You are
working for a software firm that is to develop a word processor. In order to
create an efficient spell checker, you want to know the frequency of occurences
of vowels and consonants.
Question 1: Write a
program which will prompt the user to enter a string from the keyboard. The program should then count and report the
number of characters in the string. The program should also count and report
the number of times each letter of the alphabet occurs in the string, and print
the frequency i.e. percentage of the total represented.
Question 2: Using one of
the methods of finding the maximum
element in an array, find the letter of the alphabet which occurs most
frequently in the sentence. Find also the letter of the alphabet which occurs
second-most frequently.
P6 Math
Simulation
Random numbers
tools Develop an abstract base class RandGen that will be used for generating random numbers or strings in
various questions. Give some supporting (mathematical) arguments for all your
work in your report. Use library
functions from the standard library like rand(), srand() and time(). I suggest you use
srand(time(0)) to seed the random number generator. Create four derived
classes RandLotto, RandDay, RandTime and
RandString. The RandLotto will
be used to generate random drawings for California Super Lotto Plus based on 5
numbers from 1 to 47 and one additional Mega number from 1 to 27. See http://www.Calottery.com/
games/superlotteryplus for Lottery
rules.
The RandDay will generate a random day of the
year, use the class Date from the textbook. Make sure you look into the case of
leap years to make it absolutely random.
The RandTime will generate a random time of the
day using class Time from textbook.
The RandString will be used as a base
class for two derived classes: RandStr
will generate a random strings at most 256 characters long and a RandMsgOfTheDay will return a random
message of the day (use a table of messages in memory - or in a file). Test all
your classes.
Use the classes from the question above to
answer the following:
Question 1: Your odds to win Lottery Find what
are your chances to win the California Super Lottery through a computer
simulation. I suggest you keep generating random Super Lotto draws in a loop
until you win, say 100 times. Try to
have a significant number of wins before you draw a conclusion.
Question 2: The Birthday Problem simulation using random numbers
Use the RandDay to find the probability that two students in the class have the same Birthday. This will depend of class size. Do a computer simulation and experiment to see what class size will make that probability to be about 1/2. Hint the answer is a number in the range from 20 to 30.
Section 2: Applications in
Physics, Biology, Economics and Social Science
Pr7. Modelling an Epidemic with Differential Equations, the SIR Model:
In the
investigation of the spread of any disease, the members of
the community
can be placed into one of three categories:
Susceptibles: those who can possibly
catch the disease;
Infecteds: those who currently have the disease and are
contagious;
Recovereds: those who have already had the
disease and are immune.
Let S=S(t),
I=I(t), and R=R(t) denote
the number of people in the
respective categories
on the t - th day of the
investigation.
If we know the
initial values S(0) , I(0) , and R(0) , we
We can
approximate future values of S , I , and R provided we know how
They are
changing. Thus we need to develop a
model based on the
rates of
change of S , I , and R . Let S'=S'(t) , I'=I'(t) , and R'=R'(t) denote the rates of change
of S , I , and R (in units of people per
day) on the t-th day of the
investigation.
Assumptions for
the SIR Model: before we can develop the rate equations S' , I' , and R' our model, we need to
clarify the assumptions underlying this model.
How virulent is the disease? What is happening to the population under
investigation (Immigration, emigration, death, birth, etc.)?After recovering
from the disease, when (if ever) do you become susceptible again?
Rate of
Recovery. The rate of recovery
tells us the rate at which people are moving from the infected population to
the recovered population. Our measles -like disease has an infection period lasting k=14 days. Looking at the entire infected population today, we expect to
find someone who has been infected for less than one day, someone who has been
infected between 1 and 2 days, and so on,
up to someone who has been infected between 13 and 14 days.
Those in the last group will
recover today. Notice that the rate of change of the recovered is positive because
the number of recovered is continually
increasing. If the infection period of a different illness is k days, instead
of 14, and if we assume that 1/k of the infected people recover each day, then
the new recovery rate is
R'(t) = ![]() · I persons per day; b =
· I persons per day; b = ![]() is called the
recovery coefficient.
is called the
recovery coefficient.
This gives us the first
piece of the SIR model.
Rate of
Transmission. The rate of
transmission describes the rate at which susceptible people are becoming
infected. The rate of transmission is proportional to the number of daily
contacts between susceptible and infected folks. The number of daily contacts
that the entire susceptible population has with infected individuals is the
product of p·I the average of the
number of infected people contact per susceptible person times the number of
susceptibles S hence equals p ·S· I
So the rate of transmission
is proportional to the product S· I . This leads us the second piece of the
SIR model.
S'(t) =
─ a·S·I persons per day.
The minus sign
indicates that S decreases over time. The constant
a is called the transmission coefficient and it depends
on the general health of the population
and the level of interaction between members of the population. (Note: the
recovery coefficient only depended on the length of the illness.) The
transmission coefficient is usually found experimentally.
We are assuming
that our total population is not changing. So
S'(t) + I'(t) + R'(t) = 0
Every loss in I is
due to a gain in R and every gain in I is due to a loss in S . So the
complete SIR model is:
S'(t) = ─ aS(t)I(t)
I'(t) = aS(t)I(t) ─ bI(t)
R'(t) = bI(t)
where a is the transmission coefficient and b is the recovery
coefficient.
We shall use the
Euler’s method program to simulate an epidemics based on this model. To solve
this we are going to use the Euler's Method for the S-I-R Model A key feature of the
S-I-R Model is that it has three rate equations, not one. Accordingly we will use the program, Euler3, which implements Euler's method for
three rate equations. We may look at
the following questions:
Question 1: At what time does the epidemic peak?
What percentage of the population is infected at this time?
How many days
does it take for the epidemic to die out
completely?
What percentage
of the total population escapes infection?
At the time the
greatest number of people are infected, how many susceptible people are there?
You may think
that we would have to solve this model for the functions S(t) and I(t) in order to answer this last question. This isn't necessary. When I(t) reaches its maximum value then I '(t) = 0 . Define some new symbols: I![]() the maximum value of I(t), S
the maximum value of I(t), S![]() the value of S(t) at the time when I(t) reaches its maximum value. Using the rate equation I '(t) = a S
the value of S(t) at the time when I(t) reaches its maximum value. Using the rate equation I '(t) = a S![]() I
I![]() – b I
– b I![]() =0 at the specific time t when I(t) reaches its
maximum, we find that S
=0 at the specific time t when I(t) reaches its
maximum, we find that S![]() = b/a which does not depend on I
= b/a which does not depend on I![]() .The value just found is called the threshold value of S(t). An epidemic
is said to occur if I(t) rises to a peak, then dies away.
.The value just found is called the threshold value of S(t). An epidemic
is said to occur if I(t) rises to a peak, then dies away.
If S(0)> S![]() , the threshold value of S, then an epidemic will occur.
, the threshold value of S, then an epidemic will occur.
If
S(0)≤ S![]() , then an epidemic will not occur.
, then an epidemic will not occur.
Now this project
is asking you to test this model using the following problem:
Suppose you are a public
health official for a school district with 50,000 students. A measles outbreak is reported in a
neighboring school district and you fear yours is next. You know that the average recovery time for
a case of measles is 14 days, and that about 2.5% of contacts between an
infected and a susceptible individual lead to infection. Suppose you estimate that on a typical day,
an average individual has a probability of 2/5000 of coming in contact with an
infected individual. If 45,400 of your
district's students are initially susceptible, will an epidemic occur? Even though the
S-I-R model has three rate equations rather than one, Euler's Method can also
be used to obtain approximate solutions to this model. Here is the S-I-R model discussed before.
S'(t) = ─ 0.00001∙
S(t) ∙I(t)
I'(t) =
0.00001∙ S(t) ∙ I(t) ─ (1/14) ∙ I(t)
R'(t) = (1/14) ∙ I(t)
with S(0) = 45400, I (0)
= 2100, R(0) = 2500
Question 2: Solve for t
≥ 0, i.e. t=0 until the
epidemics vanishes.
Based on our analysis of the
S-I-R model, and the study the graphs for S(t) , I(t) , and R(t) can you recommend some
measures which would prevent an epidemic in your district?
Discuss if an
epidemic can be avoided by for some
different initial data?
Question 3: Sketch graphs of I(t) and S(t) in this case .
Study the graphs
for S(t) , I(t) , and R(t) and use those to support your
views.
What happens to
I(t) before it reaches is maximum value?
What happens to
I(t) before S(t) reaches the value S![]() ?
?
What happens to I(t) after it reaches is maximum value?
What happens to I(t) after S(t) reaches the value S![]() ?
?
P8 Exponential and Logistic Model
Logistic Model for Population Growth
The following
equation called the exponential model describes the population of the United
States from 1790 to 1860
P'(t) = .0298 P(t), P(1790) =
3.9
One can see that
a formula for the solution could be written in terms of the exponential
function :
P(t) = 3.9 e![]()
As a population
increases, it often begins to encounter limitations in the resources which
support it. The per capita growth rate
will generally no longer be constant.
The exponential model can be modified to incorporate the effect of these
resource limitations. The resulting logistic
model often describes the growth of real populations well.
Before 1860 the
rate of growth of US population was described by an equation like P' = k P, hence the per capita growth rate P¢/P was constant
P¢/P = k.
After 1860 the
per capita growth rate of the U.S. population began to decrease. Because of this, the assumptions of the
exponential model are not valid for this period and a new model is needed. The logistic model includes the effect of competition within the population for limited resources - food, housing,
health care, etc. This competition,
proportional to P![]() = P × P because it is due to interaction of the
population with itself, reduces the rate of growth:
= P × P because it is due to interaction of the
population with itself, reduces the rate of growth:
P ' = k P – a P![]() or ( 1/P) (dP / dt
) = k – a P.
or ( 1/P) (dP / dt
) = k – a P.
This suggests
that if the logistic model holds, then the per capita rate should be a linear
rather than simply a
constant function of the population.
Year t : 1860
1870 1880 1890 1900 1910
1920 1930 1940
P(t): 31.4 38.6 50.2 62.9 76.0 92.0 105.7 122.8 131.7
A plot of P ' / P
vs. P shows that this relationship is close to
linear with a
P-intercept of 0.0318 and a slope of - 0.000170 .
The model for
U.S. population during this period is thus
P '/ P
= 0.0318 - 0.000170 P
P(1860) = 31.4 or
P' = 0.0318 P - 0.000170 P![]()
P(1860) = 31.4
By the theorem
on the existence and uniqueness of solutions to IVP (initial value problems)
the logistic equation:
P' = a P - b P![]() , a , b constants
, a , b constants
has a unique
solution satisfying each initial condition P(t![]() ) = P
) = P![]() .
.
To get some idea
of what solutions to the logistic equation might
look like, we
can examine its slope
field. A value of y for which F(y) = 0 is called an equilibrium value for the differential equation y' = F(y) . (Something which is at
equilibrium doesn't change. Since y' = 0 at an equilibrium value, the solution y(t) starting at this value remains constant.) The equilibrium values for the logistic
equation P' = aP - b P![]() is P=a/b.
is P=a/b.
Question 1: We are going to focus now on numerical
solution by Euler's Method for the exponential
model
P'(t) = .0298 P(t), P(1790) = 3.9
describing the population of the United States from
1790 to 1860
Use the program
Euler1 to estimate the size of US population
at 1860.
Estimate then
the population size at 1880, 1900, 1920 and 1940 and compare to the values
given in the table above.
Question 2: As we notice that the exponential model does
not work any more after 1860, let us use the logistic model and calculate the
size of US population from 1860 to 1940 using the program Euler1.
Between 1860 and
1940 the population of the United States follows a logistic model:
P'(t) = .0318 P(t) - .00017P![]() (t) ,
(t) ,
P(1860) = 31.4
Redo the numerical calculation using the logistic equation for the whole interval [1790, 1940]
P'(t) = .0318 P(t) - .00017P![]() (t) ,
(t) ,
P(1790) = 3.9
Graph also P(t)
for both methods, on the corresponding
time interval and
Graph also the
the solution for the logistic model on the whole interval and compare and
comment your results.
Question 3:
We are actually applying this model to the population from 1790 to 1940
to better understand the differences between this model and the exponential
model.
In what year does
the difference between these two models become noticeable? If the exponential model had held until
1940, what would the population of the United States have been in 1940?
What happens to
solutions of the exponential model as t®∞ What
about solutions of the logistic model?
How can you tell?
P9. Modeling
Fermentation
This project uses Euler’s method and the corresponding computer
programs to study the model of fermentation. Yeast growing in a solution
(such as grape juice) containing sugar
consumes the sugar and produces alcohol as a waste product. This
process is called fermentation. The alcohol is toxic to the yeast, however. When the concentration of alcohol in the solution has reached 8 - 12% , the yeast is killed and fermentation stops.
By periodically
measuring the concentration of sugar, one could add sugar as needed to keep its concentration in the solution
constant. Suppose one could also
extract the alcohol as it was produced so that
the yeast experienced no toxic effects.
Under these conditions, it is
reasonable to assume the yeast are growing logistically . Let Y(t) denote the yeast population size at time t .
Suppose Y(0) = 0.5 lbs of yeast, the carrying capacity of the solution is k/a = L = 10 lbs of yeast; (this is the size the population
approaches as t → ∞ )
and the intrinsic growth rate is k = 0.2 lbs of yeast per hour, per
pound of yeast. (The intrinsic growth
rate is the per capita growth rate in the absence of competition.) The
model for the yeast population as an initial
value problem:
Y ' = k∙Y ∙(1 ─ ![]() Y) or Y ' = 0.2 ∙ Y ∙(
1 ─
Y) or Y ' = 0.2 ∙ Y ∙(
1 ─ ![]() Y)
Y)
Y(0) = 0.5 with Y(0) =
0.5
Question 1: Use
the program Euler1 to solve your
initial value problem.
Run from t![]() = 0 to t
= 0 to t![]() = 100 hours setch the
graph of Y.
= 100 hours setch the
graph of Y.
Find the
following times:
- the time when Y(t) ≈ 0.5 L , (half the carrying capacity)
- the time when Y(t)
≈ 0.99 L , (within
1\% of the carrying capacity)
(use the table of values or the graph to help you determine these)
Suppose a
different strain of yeast has an intrinsic growth rate k = 0.1 , half that of
the strain you have just modeled.
If everything else remains the
same, how do you think the solution will
change? Will this strain reach
half the carrying capacity more or less
quickly? Will it get within 1% of the carrying
capacity more or less quickly?
Question 2: Use the program Euler1 again with this new
value of the intrinsic growth rate and
check your predictions. Sketch this
graph on the same pair of axes
as your original graph,
indicating the times at which
it reaches 0.5
L and 0.99 L .
Yeast, Alcohol
a 2 parameter model
We now consider
a situation in which the sugar concentration is held
constant but
alcohol is not removed. Let A(t) denote the amount of
alcohol in the
solution at time t . When the yeast is first introduced into the
sugar solution (at time t = 0 ), how much alcohol is present?
(Remember --- the alcohol is produced by the yeast as a waste product.) Answer:
A(0) = 0. Suppose each pound of yeast produces 0.05 lbs of alcohol per
hour. The differential equation which
describes the growth of the amount of
alcohol in the solution is
A' = .05 Y
Since alcohol is
toxic to yeast, the differential
equation for the
yeast population
will have to be modified.
Suppose that a
pound of alcohol will kill 0.1 lb of
yeast per hour, per pound of yeast.
Modify the logistic equation for
Y(t) to take this effect into account. Continue to use the parameter values k = 0.2 and k/a= L = 10 .
Y '(t) = 0.2 ∙ Y ∙( 1 ─ 0.1 Y) ─ 0.1 AY
Sketch below your qualitative
predictions for the
solutions to the coupled differential equations for A(t) and Y(t), using the initial values
A(0)=0,Y(0)
= 0.5 .
Question 3:
Use the program Euler2 and modify it to solve your initial value problem
for A(t) and Y(t) . This program
uses Euler's Method to solve an initial value problem for a coupled system of two differential equations
Run the program with t![]() = 0 to t
= 0 to t![]() = 100 hours and adjust the display parameters so you can see the graph clearly. Both graphs and a table of
values will be displayed. Sketch your graphs below, indicating the following
times:
= 100 hours and adjust the display parameters so you can see the graph clearly. Both graphs and a table of
values will be displayed. Sketch your graphs below, indicating the following
times:
- the time when Y(t) reaches 99% of its limiting value.
- the time when
fermentation ends (what criterion will you use to decide this?)
- what is Y(t) as t →
∞
- how does this
compare to the carrying capacity in the absence of alcohol?
- how much alcohol is eventually produced?
Question 4:
Modify the model you used in by increasing the rate of alcohol
production from 0.05 to 0.25 lbs of alcohol per hour, per pound of yeast.
How is the time required to end fermentation affected? How is the final amount of alcohol affected? Make a prediction, then run the
program to test it.
Return the rate of alcohol production to 0.05 , then
reduce the toxicity of the alcohol from 0.10 to 0.02 lb of yeast per hour, per
pound of alcohol and pound of yeast. How is the time required to end fermentation affected? How is the final amount of
alcohol affected? Make a prediction, then run the program to test it.
Now leave the toxicity of alcohol at 0.02 but increase the rate of alcohol production again to 0.25.
How is the time required to end
fermentation affected? How is the final
amount of alcohol affected? Make a
prediction, then run the program to test it.
Yeast, Alcohol, and Sugar a 3 parameter model
Under the usual
circumstances of wine-making, the sugar concentration
is not kept constant. Instead, the sugar is consumed by the yeast. Let S(t) denote the amount of sugar in the solution
at time t . If each pound of yeast consumes 0.15 lb of sugar per hour, write a differential equation for S .
S' = − 0.15 Y
Since the amount of sugar will vary with
time, the carrying capacity of the
solution for yeast will also vary with time. Modify the differential equation
for Y(t) which you used above so
that the carrrying capacity with S lbs of sugar would be 0.4 S lbs of yeast in the
absence of alcohol. ( Note: Since alcohol is present your equation should
still reflect this.)
Y '
= 0.2 ∙ Y ∙( 1
─ ![]() Y) ─ 0.1 AY
Y) ─ 0.1 AY
Keep the
differential equation for A(t) which you used above.
Question 5: You now have a system of three coupled differential equations:
A ' = .05 ∙ Y
Y ' = 0.2 ∙ Y ∙ (1 ─ ![]() Y) ─ 0.1∙ A∙Y
Y) ─ 0.1∙ A∙Y
S ' = − 0.15∙Y
with initial
values A(0) = 0 , Y(0) = 0.5 , and S(0) = 25
Use the program
Eulers3 to find out how this system
behaves. Sketch the graphs of A(t) , Y(t) , and S(t).
How long does it
take before there is only 0.01 lb of
yeast left? How much sugar has
been produced by that time? How much alcohol has been produced by that time?
Discuss the role
of the intrinsic growth
rate parameter, k , in the
logistic model for yeast growth. How was growth and long-term behavior affected
by using different values of k ?
Discuss the role
of the rate of alcohol
production and the
toxicity of alcohol in the ``Yeast
and Alcohol'' model. Again, how did
using different values for these parameters affect growth and long-term
behavior?
P10. Math
Modeling in Physics: Newton's Cooling Law
We may
use either the Euler’s method or
the Runge-Kutta’s method and the
corresponding programs developed in a previous
project to solve a problem that uses Newton's cooling law. This law
describes the temperature T(t) of an object cooling from a high initial
temperature T![]() when dropped into a liquid
called ambient that remains at a lower temperature T
when dropped into a liquid
called ambient that remains at a lower temperature T![]() . We assume the ambient temperature remains constant. Newton's Law of
cooling asserts that the rate of change of the temperature of the object that
is cooling is proportional to the difference in the temperature of the object
and the ambient. Expressed as a formula it is given by the differential equation (where k is a constant of
proportionality):
. We assume the ambient temperature remains constant. Newton's Law of
cooling asserts that the rate of change of the temperature of the object that
is cooling is proportional to the difference in the temperature of the object
and the ambient. Expressed as a formula it is given by the differential equation (where k is a constant of
proportionality):
T(t) '
= - k (T (t) - T![]() )
)
Question 1: Using Runge-Kutta method solve this equation and obtain an
approximate solution when T![]() =70, T
=70, T![]() =300, k=0.19 on the time
interval t=0 to t=20
=300, k=0.19 on the time
interval t=0 to t=20
using various t
increments ( try .1, then .01 and .001). Compare your solution to the exact
solution given by: T(t)= T![]() + (T
+ (T![]() - T
- T![]() ) e
) e![]()
Question 2: Print a table of approximate T- vales,
exact T-values and the difference between them. Graph our numerical answer as
well as the exact solution In your
report consider and comment the following
aspects:
- our answer is an
approximation of an ideal exact solution
- the model itself is not an exact representation of a real phenomenon,
some assumptions are made, what
is being simplified and omitted?
- what would be the validation for our
solution and for our model ? How do you know if the model works?
P11. Economic models using linear algebra
.
The following
problem follows the method developed by W Leontief (winer of Nobel prize in
economics 1973) Consider a simple society composed of three peoples a farmer
that grows all the food, a taylor that makes all the clothing and a carpenter
who builds all the housing. We assume that they trade their products among
themselves and everything that is produces is consumed so no commodity enter
or leave their system, that is called
the closed model.
Assume now that
the proportion of each of the commodities consumed by each person is given in
the following table (sum on columns makes 100%) :
|
|
Food |
Clothing |
Housing |
|
Farmer |
40% |
20% |
20% |
|
Tailor |
10% |
70% |
20% |
|
Carpenter |
50% |
10% |
60% |
Let x1 , x2 and x3 denote the income of the farmer, tailor and carpenter
respectively. Next we are going to set up equations that require that the consumtion
of each individual equals its income.
0.4 x1 + 0.2 x2 + 0.2 x3
= x1
0.1 x1
+ 0.7 x2 + 0.2 x3 = x2
0.5 x1
+ 0.1 x2 + 0.6 x3 = x3
Using matrix
notation if
X =![]() and A =
and A = 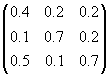 we get A X = X
we get A X = X
A is called the consumption or input-output matrix and the
equation AX = X is called the
equilibrium condition. It can be proved that under suitable conditions, (it is
enough that the last row and the last
column have non-negative entries) this system of linear equation has a positive
(consisting of all positive values) solution, in fact a one dimensional
solution set generated by a non-negative solution, see Theorem 3.12 p177 [
F,I,S]
Now in real
world it may happen that there is an outside demand for each of the commodities
produced, say the demand will be d1 , d2 , and d3 respectively and this is the “open model”.
Assuming the demand matrix is
A = ( ai,j ) with i, j =1,2,3
the equations for the the “open model” are given by X – AX = d , where d = ![]() .
.
The “equilibrium equation”
is (I − A) X = d, hence it
can be solved as
X = (I − A)-1
d. To see that the solution is positive
one can use the analog of the formal expansion of the “geometric series “ 1+ t+ t2 + … = ( 1 − t)-1
replacing t by A (one can prove this will work under suitable
assumptions).
Now we are going to solve our systems and find the incomes x1
, x2 , and x3
For each of the two models above:
Question 1: Develop the
tool for solving the system of linear equations
Write a function
(method in Java or C++) that inputs a matrix
then perform Gaussian elimination on this matrix and outputs the result.
You may have to exchange rows if a coefficient is zero in the wrong place. Then
write a program to use this function to solve a system of linear equations in 3
variables.
Question 2: Solve the closed
model problem using the program from question 1 and find the solutions x1
, x2 , and x3
representing the incomes when
A =
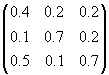
Verify your solution in the original problem
Hint: a possible
solution is 25, 35, 40.
Question 3: Solve the open
model problem using the program from question 1 and find the solutions x1 , x2 , and x3 representing the incomes when
A =
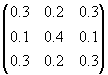 and d =
and d = ![]()
Verify your solution in the original problem
(Answer: the solution is 90, 60, 70)
Section 3: Supplemental projects
SP1. Menu driven conversion program
Write a
menu-driven program to convert measurements from miles to kilometers, feet to
meters, degrees F to degrees C. Use function subprograms to carry out the necessary conversions. Input:
OPTION, MILES, FEET, DEGF
Output:
Equivalent of MILES in kilometers, of FEET in meters, and of DEGF degrees Fahrenheit
in degrees Celsius.
Sp2. Miscellaneous math questions: finding the GCD, base conversions, Fibonacci numbers, Pascal’s
triangle
a) Greatest common divisor GCD using the
Euclid algorithm
Write a
program to calculate the greatest common divisor of any finite set of integers. Use a function GCD to calculate the GCD of a pair of
integers based on Euclid's algorithm. This is based on the remark that
GCD(a, b) = GCD (b , a%b) where a%b is the
remainder when dividing a by b.
Then use this to calculate the GCD for an
arbitrary set of integers
Use
Input: a set of integers, Output:
the GCD of the integers
b) Base
conversions
Binary 2 Decimal . Assume that an input string consists of a
string of 32 0's and 1's representing a
binary number. Write a program that will convert this binary integer to its
base 10 representation.
Decimal 2 Binary. Given a string
representation of an integer in base 10
convert this integer to its binary representation. The output should
consists of a
string of 32 0's and 1's representing
the binary number.
c) Fibonacci
numbers Write program to iteratively compute Fibonacci numbers (named after
an Italian mathematician). Some
Fibonacci numbers are 1, 1, 2, 3, 5, 8, ... where the next number is
found by summing the preceding two numbers.
Your program will read in a number, like 7, then report the first 7 numbers. in this case
1,1,2,3,5,8,13. Your
program is not assured of receiving good data,
thus if -2 is received as the number of numbers, then an error should be
reported.
d) Pascal’s
triangle. Write a program, Java
application or applet to calculate the first n ( assume the user enters the
integer n) rows of the Pascal triangle
having the
property that each row begins and ends with ones and every element is the sum
of the two entries just above it.
.On demand
display the first n rows of the Pascal triangle, a range of rows
or just an individual n-th row . Test by displaying the first 10 rows , the
range 7:12 (rows 7 through 12) or the
row 15. The display of the first rows should looks like this:
1
1 1
1 2
1
1 3
3 1
1 4 6 4 1
. . . . . . . . . . . .
SP3 Implementing mathematical
notions and abstract data with C++
a) HugeInt add
and multiply Write a function to add two large integers of any length, say
up to 200 digits. A suggested approach is as follows: treat each number as a
list(array), each of whose elements is a block of digits of that number (say
block 4 digits). For example the integer 123456789101112 might be stored with
N(1)=1112, N(2)=8910, N(3)=4567, N(4)=123. Then add the two integer (lists)
element by element, carrying from one element to the next when necessary. Then
write a function to multiply two large integers of any length, say up to 100
digits. Test your functions in the main
program that reads two large integers
calls the functions and finds
their sum and product.
b) Create a
class RationalNumber with the following capabilities and test all
member functions and overloaded
operators:Create a constructor that prevents 0 on the denominator in a
fraction, reduces (or simplifies) fractions that are not in reduced form
(lowest terms), and avoids negative denominators. Overload the addition, subtraction, multiplication,
and division operators for this class. Overload the relational < and > and equality = = operators
for this class.
c) Create
a class Complex Create a class that
enables operations on so called complex numbers. Enable input and output of
complex number through the overloaded << and >> operators (you should modify or remove the print function from the
class). Overload the multiplication *
and the division / operators. Overload the = = and != operators.
d) Consider
the class HugeInt as in the previous first question The class enables operations on integers
larger than the largest 32 bit integer(about 2 billions). Test first all capabilities of this class,
describe precisely how it operates and what restrictions it has. Overload
multiplication * and division / for this class. Overload the relational < , > , assignment and equality = = operators for this class.
e) Polynomial class Design and implement a class
for polynomials
with integer coefficients. The
coefficients and the degree are data members.
The class operations should
include addition, subtraction, multiplication and evaluation of a
polynomial. Overload +, - and * and
implement the evaluation as a member function with an integer argument. The
evaluation member function returns the value obtained by plugging in its argument
for x and performing the indicated operations. Include a copy constructor,
overload << and >> . Write a driver program to test
each of the capabilities of this class.
SP4 Calculators simulators
a) HugeInt calculatorModify the
calculator applet Chapter 6 of the
textbook to perform huge integer arithmetic. You are going to manipulate
integers with a large number of digits, let's say about 50 digits. You need to
create a HugeInt class .Let the user chose the exact size of HugeInt at
runtime. Addition and multiplication are not too bad, Subtraction, signed
arithmetic, and division are much more difficult .
b) Enhanced calculator applet
Modify the
calculator applet in the given handout:
to have a key for each of exponential, natural log, sin, cos and tan trigonometric functions (and
possibly the inverse trig functions); to perform BigDecimal arithmetic (an
arbitrary number of decimals); to use the Expression Evaluator; to act lilke a
graphing calculator, graphing both functions you enter as a sequence of key commands (ended with
the = sign) or entered as a string as input to
the Expression Evaluator.
c) Enhancing the
Expression Evaluator Class Compile and test the Expression Evaluator class from your
textbook (Horstmann: Java Concepts Ch.17). You may notice the original code is
not fault tolerant and does not know what to do if the input string has errors.
Rewrite this class and make it able to deal with the following type of errors
(I suggest using exception handling):
- non-numeric
fields when numeric is expected;
- wrong sequence
of operators like */ or +* or ** etc;
- wrong usage of
parenthesis, like unmatched ( and ) or starting with ).
A second
enhancement will be to rewrite the class to keep the above syntax error
detection and correction and also allow the usage of named variables (that have
been previously initialized) of trigonometric and inverse trigonometric
functions, exponential and logarithm.